| |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Feb 28 2024 Progressing nicely. Channels now compile and run. I am working on SDL3 and X64 Windows concurrently. Patching in the missing Posix functionality into Windows/X64. ie: I devolve to the GPUChannel. It has a "Dynamic Command Interface." Here are the first 16 commands. #define GPU_NOP 0x00 #define GPU_COPY 0x00 #define GPU_FILL 0x01 #define GPU_BLIT 0x02 #define GPU_CLEAR 0x03 #define GPU_SETAPEN 0x04 #define GPU_SETBPEN 0x05 #define GPU_DRAW_LINE 0x06 #define GPU_DRAW_RECTANGLE 0x07 #define GPU_DRAW_ELIPSE 0x08 #define GPU_DRAW_IMAGE 0x0A #define GPU_DRAW_POLYGON 0x0B #define GPU_SPLINE 0x0C //next stream is a spline. #define GPU_CHANNEL_DATA 0x0D // double buffered asynch background processing. #define GPU_PROCESS_MATH 0x0E // #define GPU_CUSTOM0 0x0F #define GPU_CHANNEL_DATA 0x10 #define GPU_CHANNEL_HMM_WHAT 0x #define GPU_CUSTOM0 0x0F #define GPU_CHANNEL_DATA 0x0D #define GPU_CHANNEL_HMM_WHAT 0x0E #define GPU_CUSTOM0 0x1F The GPU sits in command mode. sending a NOP says next instruction sets the stream bit width This allows us to send 16 commands in 1 write! GPUChannel.write(GPU_NOP,char tSize); 1111,1111,1111,1111,1111,1111,1111, //--------------------------------- // Primitive type bits xxxx x111 #define DATA_BYTE 0 #define DATA_SHORT 1 #define DATA_CHAR 2 #define DATA_INT 3 #define DATA_LONG 4 #define DATA_FLOAT 5 #define DATA_DOUBLE 6 #define DATA_OBJECT 7 //-- array dimension bits xxx111xxx #define DATA_P 0 // 1 primitive #define DATA_ARRAY 1 // array of primitives #define DATA_2D_ARRAY 2 //2d... #define DATA_3D_ARRAY 3 #define DATA_4D_ARRAY 4 #define DATA_8D_ARRAY 5 #define DATA_CUSTOM0_ARRAY 6 #define DATA_CUSTOM1_ARRAY 7 //-- Parameter address mode bits 11xxxxxx #define EBIT_1 0b01000000 // Address mode 0 - Parameter address mode bits #define EBIT_2 0b10000000 // Address mode 1 - 8,16,32,64 bits #define BYTE_ADDRESSING_8 0x00 #define BYTE_ADDRESSING_16 0x01 #define BYTE_ADDRESSING_32 0x02 #define BYTE_ADDRESSING_64 0x03 //--- Data primitive definition bytecode details // Primitive type bits xxxxx111 // Array dimension bits xx111xxx //-- Parameter address mode bits 11xxxxxx #define GET_DATA_TYPE(input, primitiveType, dimensionBits, addressMode) do { \ primitiveType = (input) & 0x07; \ dimensionBits = ((input) & 0x70) >> 4; \ addressMode = ((input) & 0xC0) >> 6; \ } while (0) #define ENCODE_DATA_TYPE(data, primitive, dimension, addressing) \ ((data) = (primitive & 0x07) | ((dimension << 4) & 0x70) | ((addressing << 6) & 0xC0)) Feb 19 2024 About time I said something here : Been a good week. I have a block of 10 days coming up. I am planning/hoping to have something released by then. ATM I am working on Setting up struct GraphicsContext. Also ThreadChannel but this involves NetXecChannel and MemoryChannel. MemoryChannel allocates GPU memory. ThreadChannel can allocate Threads on the GP & needs MemoryChannel. NetXecChannel ThreadChannel needs NetXecChannel to actually run. Nothing runs without NetXec. ContainerChannel Containers are your main interface. Usually a Window. A zip file is a container without a window. A container contains. ScreenChannel Think of this as your Desktop. Channels run in parallel and are non blocking. This makes making the startup code a serious challenge. I am on it. This past week I finally got the Threads working preemptively on X64/Windows. Last year I spent weeks on end going through Linux & Windows with MinGW64 in the middle. From Kernel to display hardware. That is when I realized that the signal interface in doesn't work because all the threads wake up when a signal bit is set. This has to do with an omission in the original posix definitions where multiple threads waiting on one object is undefined. To get it to work I wait on a whole byte. This gives the preemptive thread independence we want and if I map 8 Objects into sequential evenly aligned, I can map them in at the thread level as bytes, and at the Command level I can control 8 threads in one stomp. ie: 64 bit NetXecChannel Thread signal
Stomp
Memory Location mapped as 8 bytes.
Channels have 4 core System Threads. Exec,Event, IO, Exception. This leaves 4 threads for other uses. These are system Threads. The ThreadChannel can allocate as many as the OS addressing will permit. AND this does NOT include GPU thread which can have (Better sit down) (64K X 64K X 10X2^31) Or there about. There is more... MUCH MUCH more. I am doing the SDL3 code and the X64 windows code in tandem. Jan 16 2024 Channels are Non blocking. These 3 Channels ALWAYS require each other. NetXecChannel: //===== The core Executor of all other channels. All IO requests are filtered through the NetXec. Does throttling and precise system. Delegates according to system load. Like Amiga exec always reserves a few cycles for system operations. There are 16 Core Channels. Each Core Channel can have 16 Subchannels. SubChannels function via Serial interfaces to their core Channels. Generaly Core Channels will require some attribute of their parent core channel. Requires MemoryChannel/ThreadChannel MemoryChannel: There are several types. HEAP,STACK,IPC,GPU,REGISTRY,PAGE GPU has several more Have yet to enumerate ThreadChannel: Allocates Thread on CPU or GPU. Requires MemoryChannel/NetXecChannel Working Here Now on GPU/"USER" Thread interface. (It's a doozy) You found me! Hi, my name is Tony. I have worked as a hardware programmer for many years. I program in C, Assembler, and Java. An explanation of what I am planning and what I have been up to. Channels: What are they and Why? Channels are non blocking/re-entrant data pipes. Think of them like a radio channel. You tune to the channel and start listening to it. All Channels are guaranteed to have these 6 functions. Open,Close,Join, Leave, Read, and Write. Channels are also only written in C, Assembler,for maximum performance. Some external libs may use C++. There are 16 CORE Channels Each Core Channel can have 16 SubChannels Any Channel can join any other Channel. With these 16 Channels we can create or control any software or hardware. Channels will be "cross platform." char *CoreChannelTypeName[] = { "system", // System (NetXecChannel) monitors threads/processes "device", // (DeviceChannel) Device Drivers. "memory", // (MemoryChannel) AllocMem(size,type) HEAP,STACK,GPU,SHM,CLOUD,REGISTRY,PAGE "thread", // (ThreadChannel) GetThread() CPU/GPU/URL. "signal", // (SignalChannel) // Signal blocks. "media", // (MediaChannel) // "clock", // (ClockChannel) // date/time register. "container", // (ContainerChannel) Containers have display window. "url", // (URLChannel) // Reach out and grab something "server", // (PortServerChannel) // default is port 23232. "process0", // (Process0Channel // BG processes "process1", // (Process1Channel) // "cli", // (CLIChannel) Channel DOS "compiler", // (CompilerChannel) gcc driver "debug", // (DebugChannel) gdb driver "nimosini" // (NimosiniChannel) for AI }; I have been working mostly on GPU code the past 3 months. This is my first blog update in almost a year. It actually took a pile of effort but I have complete control of the GPU now. I am at a plateau. The Channel interface now mounts the 16 code channel R/W buffers at start. Latest Channels structure Jan 19 2023 Since I have been working on HyperView3.0 in C for the past 6 months, I have neglected the Java HyperView2.99 upgrade to from JDK11 to JDK19. This involves rewriting Applet. I have this already well underway with a new almost verbatim drop in class called I estimate 3 days to complete version 1. Aug 7 2022: Added these control bits for HyperView3.0 // HyperView main enable bits. Some of these are deprecated //HyperView->flags1 #define int DISPLAY_ENA = BIT1 // before we overflow 32 bits #define int CONNECT_ENA = BIT2 // will split some of these #define int KEYBOARD_ENA = BIT3 #define int CONSOLE_ENA = BIT4 // Enable stdin #define int TEXT_ENA = BIT5 // Enable System Text rendering/ #define int GOB_ENA = BIT6 // Enable Bittable Gobs() #define int LINE_ENA = BIT7 // Enable System lines buffer. #define int MENU_ENA = BIT8 // Enable X style pop menu. #define int OUTLINE_ENA = BIT9 // draw outline in current FG Color #define int LAYER_SWAP_ENA = BIT10 // enable Component Layering. #define int KEEP_RUNNING = BIT11 // Asynchronons non blocking quit signal bit. #define int BACKGROUND_ENA = BIT12 // Enable background image rendering. #define int DEBUG_ENA = BIT13 // Enable running under debugger #define int MENU_ACTIVE = BIT14 // render pop up menu. #define int RUN_EXCEPTION = BIT15 // Oh Oh! Trigger exception handler. #define int BACKGROUND_LOADING = BIT16 // Background Image is still loading. #define int IMAGE_LOADING = BIT17 // Will do extra rendering while loading. #define int GOB_BOUNCED = BIT18 // It bounced, invoke Spline momentum/direction instructions if enabled. #define int TITLEBAR_ENA = BIT19 // Enable the titlebar at the top. #define int CONNECTED = BIT20 // -- You are connected to a server. #define int CONNECTING = BIT21 // you are in the process. #define int RUNSTACK_TIMER = BIT22 // How long to run the display at this display stack. #define int GURU_ENA = BIT23 // OH OH! someting failed. #define int GEM_REFRESH = BIT24 // Redraw the "Connect Gem" color on the titlebar when connection state changes. #define int OBSERVER_ECHO = BIT25 // print all Image Obeserver messages to stdout. #define int INIT_OVERRIDE = BIT26 #define int SKIP_RESTORE = BIT27 // flag a 1 display frame #define int PARENT_IS_HYPERFRAME = BIT28 // If I know the parent Component is a HyperFrame, I can call it's methods. // Note: HyperFrame is deprecated for java 12. // // Wait for text to time out. Note this will run for() // If the text does not actually time out and does not cancel // a regular runView timeout #define int WAIT_TEXT = BIT32 // // A note on USE_BLIT_OPTIMIZE. // This controls how the background clip restore blit is done. // 1) Restore only the damaged part of the display caused by component moves and layer changes. // 2) Stamp the entire display in one blit and then do the component render. // #1 is generally faster as blits are small things like sprites so you are restore // #2 However, if you have a LARGE number of gobs, it will be quicker to stamp the whole background // than to loop through and restore a pile of individual clips. // FTM:You will have to determine which is better for you. // TODO: Make this automatic via time based calculation. // // Main View Flags 2 HyperView->flags2 #define int BACKGROUND_UNDERLAP = BIT1 #define int BACKGROUND_STRETCH = BIT2 #define int EXTERNAL_SERVER_ENA = BIT3 #define int SERVER_SPAWNED_VIEW = BIT4 #define int GEM_UPDATE_OVERRIDE = BIT5 #define int ERASE_VIEW = BIT6 // Erase signal #define int USE_BLIT_OPTMIZE = BIT7 // Blit clip only bit (as opposed to whole display) What you are #define int INITIALIZE_REFRESH = BIT8 Aug 32022 Latest structures for the ContainerChannel. struct Color { Uint32 argb; }; struct ColorOperation { struct Color foreground_color; struct Color select_color; void *transform; }; struct Point { struct Linkable; int x,y,z; struct ColorOperation *color; }; struct GraphPoint { struct Point point; struct ColorOperation *color; }; struct Window { struct Linkable node; SDL_Window *base; void *parent_screen; Uint32 x,y,z,x2,y2,z2; Uint32 width,height; }; struct Screen { struct SDL_Rect rectangle; SDL_renderer *screen; }; struct Graphics2D { struct Linkable node; SDL_Window *main_window; SDL_Renderer *renderer; int x,y,z; int width,height,depth; struct HyperLinkedList blitterList; Uint32 fgPen; Uint32 bgPen; }; July 30 2022 Uploaded these albeit sad docs :O Abort.html TEST LINK July 18: Working on ContainerChannel A Container is a displayable area of video RAM that you can put various displayable Components into. struct ContainerChannel { struct Channel base; SDL_window *window; SDL_surface *gpu_ram; SDL_texture *heap_argb_ram; HyperLinkedList *orange_list; int *pixels; }; July 12: Still working through the Channel startup. Added a pile of new structures many of which are java analogues. Color, Palette, Graphics2D, Point, Clip, CarteaseanPoint, Image, TitleBar, Gadget, Dispatch,GraphPoint, Graph, Buffer (as in NIO), //=============== // latest Base Channel structure struct Channel { struct Linkable node; int channel_flags; int type; int io_flags; int pid; long atomic_id; long ipv6[2]; // struct Signal ch_signal; char name[64]; struct RunInfo run_info; struct Signal signal; struct HyperLinkedList channel_link; //----- struct HyperLinkedList io_list; struct NetXecThread io_thread; SDL_mutex *io_lock; void (*paint)(struct Graphics2D); // The lone function pointer }; July 10: Programming groups I am in. Simple Direct Media Layer Videolan VLC/LibVLC NVIDIA/CUDA W3 Consortium Seamonkey Not including ones I my follow. Everything I use I have compiled including the compiler. ATM I am using version 12. I was patched up to 13.03, but there was serious issues. Tools Page Latest Channels structure June 26: Tons of changes. Made several big changes to the IOBLock interface. I am right at the point where I am trying to link. Fixing invalid offsets and dangling references. System Channels: What are they?? SystemChannels are the basic channels that give you direct access to the underlying hardware. Any Channel you create you will assemble out of system channels. Together all system channels combined give you access to 100% of the allowable underlying device control. There are at this juncture 17 SystemChannels. SystemChannel; AKA NetXecChannel. Process/Thread/RunInfo monitor and control DeviceChannel Open and control underlying hardware drivers. MemoryChannel 5 types of memory Heap,Stack,GPU,IPC,Cloud, and Registry. ThreadChannel Creates/dispatches thread on CPU or GPU. SignalChannel Creation & assignment of hardware bases signal bits. ArbitrationChannel Monitor/Lock arbitrator. MediaChannel Audio mp3/wav/Blit Video/VLC driver ClockChannel Asynchronous 1 second clock & timer interface ContainerChannel Screen/Window graphics/svg load & save/blitter functions. URLChannel URI fetcher ServerChannel Non blocking single process select socket server. ProcessChannel Background number crunching. StateMachineChannel function/state allocation and control CLIChannel command line interface CompilerChannel Multi language compile/link DebugChannel debugger interface NimosiniChannel AI channel Signals: I am an NVIDIA developer. I spent many weeks going over windows/posix threads and the signals incongruities. I had designed an interface that had 15 bits of resolution compressed to 8 bits. But when I start working on CUDA, I realize it had over 1000 in GPU threads!!! That requires a hell of a lot more signals than 15! So 32 system signals at the operating system level. Many of these are already reserved for mouse/keyboard/windows etc. Will have to test how many are left over. 1 is enough. 512 extended signals via a SignaGroup. This is a compromise as opposed to always allocating 1024. New structure #define SIGNALGROUP_BLOCK 0x000000ff; struct Signal { char *name; int signal; int signal_enable; void *reply_function; struct Signal *next_signal; }; // revamped struct SignalGroup { struct Signal *signal[SIGNALGROUP_BLOCK]; void *reply_function [SIGNALGROUP_BLOCK]; struct SignalGroup *next_signal_group; }; ATM Mashing/compiling/linking :) Code Babble.Sat June 11 2022
Graphics
Hardware Layers: I have done a
pile of work this week. Went through every single
library I am using one by one
and there are many. Made a test program and one by one linked/tested and dumped the ones that didn't work. plus weeded out all yet to to be documented deprecated functions in SLD and have all the latest defs patched in. Spent much effort with SDL_Video. Not ready yet as most code is transitioning from Version 1. Spend much of yesterday working on ContainerChannel and ThreadChannel. System Channel refactoring. There are now > 4 < Channel types for > Web 4 < BaseChannel All Channels encapsulate a base channel. SystemChannel There are 32 System channels. These Channels are generally Singletons. (but don't have to be) CompositeChannel, SubChannel After much time mulling over everything, I have decide to limit New 32 bit Signal structure struct Signal { char *name; int signal; int signal_enable; void *reply_function; }; //-- Drastically increase the amount of signals for SignalGroup to accomodate GPUChannal. // revamped struct SignalGroup { struct Signal *signal[0xff]; void *reply_function [0xff]; }; struct NetXecSignal { int signal; int totalbits; int maxbits; }; This is how the runtime stack layer init() wraps the SLD thread creation call for init() and pause() states. This hopefully will tie up the loose ends of the Posix committee relevant to signal dispatch on concurrent waiting threads. Right now they all wake up. I started working with CUDA and have the latest tools and libraries. Going to map out a common interface with ARM8/Adreno. Have that all installed. Got VLCChannel linked and compiled. Recompiled vcl. failed. Still running in 32 bit mode. Can't afford the time to port over the thousands of object necessary. Will continue to drive VLC as a process in 32 bit till the 64 bit libVLC upgrade is stable.
w WW We have 2 types of displayable "Bitmaps" 1)An unprocessed main memory raster comprised of 32 bit ARGB data. "This is the analogue to a java MemoryImageSource." 2)A copy of this data in GPU memory that has been scaled according to the width/height resolution/color model and pixels per inch of the target display. These are your accelerated images. The function of the GPUChannel is to allow access to the concurrent capabilities of the GPU. Off to work on ThreadChannel more. My latest NVIDEA Developer upgrades have wiped out my shadowplay so no more video till I get a new machine. Machine is available. I just have to go get it from my Engineer. I also need a new monitor for my ARM8/SnapDragon box but that's another story :) What is the Channel Paradigm and why. The Channel Paradigm is an abstraction that completely homogenizes all hardware and software. It is in this regard like a device. All Channels have these capabilities. 1) Any Channel can join any other Channel 2) Any Channel can listen to any other Channel. 3) Any Channel can write to any other Channel. 3) All Channels are Non blocking and reentrant and can never deadlock. 4) Channels are only written in C or Assembler. 5) All Channels extend the BaseChannel 6) When complete Channels will be completely "Machine generated" 7) Final stage the AI will create Channels on command. Why?
This is my social interaction/media site. I am one person plugging away at this. This is going to be my OWN Social interaction/media site. I am writing the back end in C language and assembler. I also have written a substantial java API. I have been working on it since Java versions 1. Tony's little java et al group on FB. Here are some docs.HyperView docs I have been working on this and the back end for over a year. I work full time in the operating room of the cardiac ICU of the 2nd largest Hospital in N.A.; I do this when I am not working. The back end is written in C and utilizes the Common Gateway Interface. On Facebook everyone gets a timeline. On MultiverseSocial, you get 3D fractal Planet located in a section of the Milky Way. I am working primarily on 5 things. 1) Java 12 upgrade for java HyperView & Component based Applet replacement classes. 2) Tony's Channel Paradigm and > Web 4 < 3) BML based Web browser & concurrent Apache mod written in C/Assembler. 4) BQL data base. 5) HTML5 HyperView interface in C driven CGI/Javascript. 5) Mongoose-C Python replacement project. Orthographic random planet map.
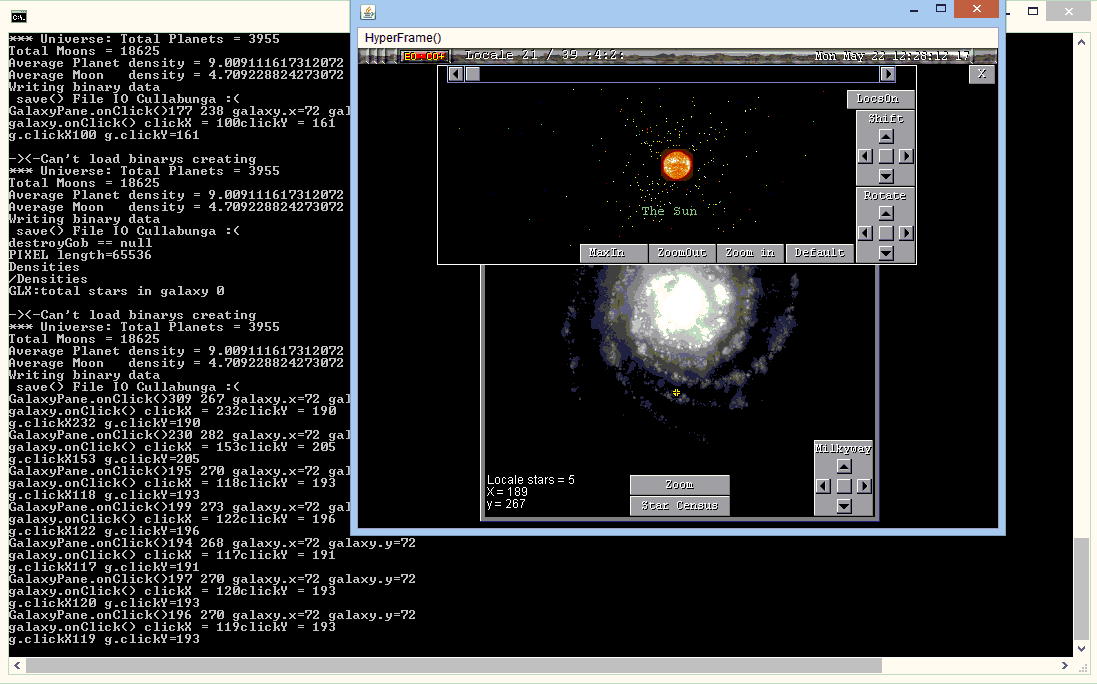
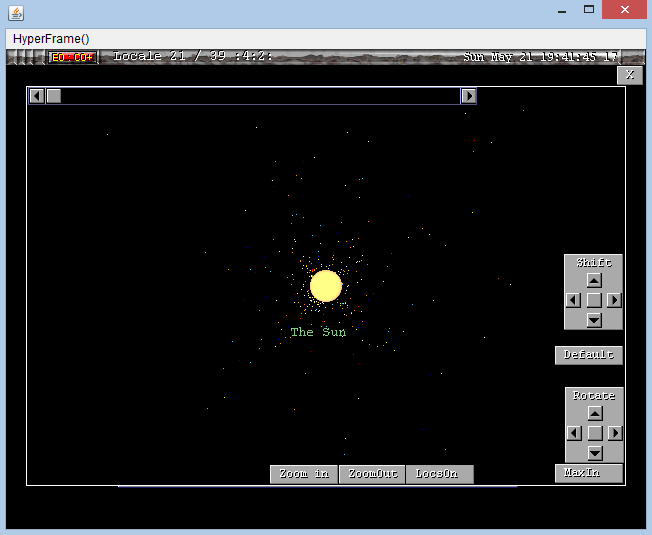
Made with HyperView2.99 
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||